
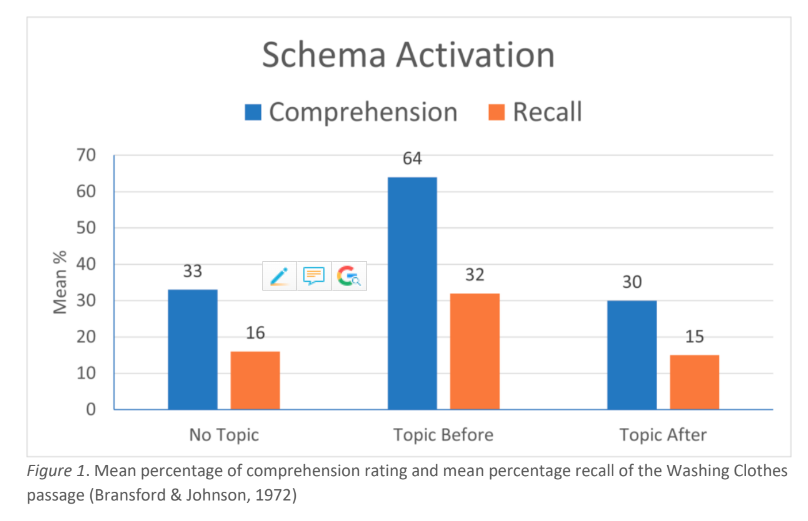
image credit: https://en.wikipedia.org/wiki/Catch_Me_If_You_Can#/media/File:Catch_Me_If_You_Can_2002_movie.jpg
In the 2002 movie Catch Me If You Can, the character played by Leonardo DiCaprio, Frank, is impressive: he successfully pretends to be an airline pilot, a Secret Service agent, a medical doctor, and is beginning to figure out a way to fake his way through the bar exam before he goes on the run from the FBI. Frank has many impressive skills that allow him to successfully pretend in these professional situations, but he doesn’t know how to fly a plane, protect the president, cure a disease, or practice law. He’s just incredibly skilled at pretending.
Some of the current discussion about so-called “artificial intelligence” reminds me of Frank. The term “artificial intelligence” is misleading: the most commonly used “AI” tools are more properly called “large language models.” These tools generate text in response to queries. If you’ve tried a tool like ChatGPT, you were probably getting text back in response to a question or request. That’s a large-language model.
I think applying the term “artificial intelligence” to large-language models is an example of anthropomorphization. We seem to want (and others want us to) imagine that ChatGPT is “thinking” and coming up with “creative” text based on our query. It’s not.
The best and most detailed description I’ve seen of how a large language model works is this explanation by Mark Riedl: A Very Gentle Introduction to Large Language Models without the Hype. Mark walks through how large-language models do what they do step by step, and ends with a great summary:
“Large language models, including ChatGPT, GPT-4, and others, do exactly one thing: they take in a bunch of words and try to guess what word should come next. If this is “reasoning” or “thinking” then it is only one very specialized form…Our first instinct when interacting with a Large Language Model should not be ‘Wow, these things must be really smart or really creative or really understanding.’”
Large-language models aren’t doing anything like what a human brain does as it processes a question and tries to come up with an answer. What ChatGPT is doing is a verbal version of the faking that Frank does in Catch Me If You Can. It shouldn’t be called artificial intelligence because the process isn’t close to how we use the term “intelligence” in humans and other animals. It’s a process that could be called something like “statistical test prediction.” It’s a complex version of the predictive text feature many of us already use on our phones or word processing apps. A large-language model uses a huge database to figure out what word or words are likely to come next in a sentence, and it strings the most probable verbal combinations together. Here’s how cognitive psychologist and neuroscientist Hernán Anlló defines large-language models:
“Language models are AIs capable of parsing human language, and responding to it with self-generated coherent bouts of human language. Their technique is as straightforward as it is powerful: language models simply predict, based on context, how likely it is for a word to be followed by another word within a sentence, and follows this probability tree to generate its own linguistic output. Incredibly, it is by virtue of this sole operation that LLMs have managed to produce the dashing performances we have come to know in the present date.” (“Do Large Language Models reason like us?”)
This is a complicated version of “faking” words, sentences, and paragraphs that sound good, are often accurate, and are generated quickly. It’s impressive! If you’ve played with ChatGPT, you’ve seen how quickly it can produce long stretches of text that are seemingly accurate (sometimes eerily accurate) responses to just about any question you ask it.
But it’s not intelligence, and it’s not what we usually call “thinking.” All this technology does is produce a “coherent bout of human language” using statistical probabilities regarding the next most likely words and phrases in a sentence. It’s impressive, it’s fast, and it may even be useful in some contexts, but it’s not intelligence and we should stop calling it that. Large-language models don’t think about the meanings of words or reason through problems deductively or inductively. Some well-meaning (I think) folks inside and outside of the education community are anthropomorphizing large-language models (like this well produced video that refers to AI as a “massive external brain,” and others who call AI products “creative.”) Humans like to anthropomorphize all sorts of things (see “Is AI the Smile on the Dog”), even when this technology makes ridiculous mistakes: when a large-language model makes a mistake, developers call it a “hallucination.” It’s not! It’s a predictable result of the technology. It doesn’t know how to think or reason, so sometimes it produces results that make zero sense or even makes up sources that don’t exist.
Large-language models don’t reason, see connections, or form and reform concepts or schemata. They fail at authentic reasoning tasks like the NYT “Connections” game (note: I often fail at that game too, but I fail for very different reasons than ChatGPT fails).
Some authors go beyond calling AI “fake”: I love this article a friend gave me (hey Chris P.!). I’ve been thinking about the implications of this article quite a bit, and I think the author’s bold claim, and new title for large-language models, might be justified. Don’t be put off by the title – the authors use the term “bullshit” for important reasons: “ChatGPT is bullshit.”
Why does it matter if we anthropomorphize large-language models and call them “artificial intelligence?” Because this kind of misrepresentation leads us to forget that we’re NOT dealing with “someone” or an intelligence when we interact with a large-language model, and that mistake may have consequences. In my field, education, there are some enthusiastic people breathlessly advocating for “AI everything” in teaching and learning. Large-language models might be useful in some aspects of teaching and learning, but we need to remember that they aren’t thinking like students and teachers, and learning requires thinking. If students “off-load” necessary cognition to large-language models, they might be able to produce convincing verbal products, but that ain’t learning.
I like this rule proposed by Allison Seitchik:
“The most important thing to note is that if you cannot validate AI’s response and information yourself, you cannot use it. You MUST validate and check every piece of information. In other words, if you cannot do the task yourself and check, don’t ask AI to do it.”
Students and teachers have to know how to do the tasks so that they can check the quality of the “coherent bout of human language” produced by the large-language model. Teachers and students have to learn and become experts in tasks related to teaching and learning before off-loading parts of those tasks to large-language models. If we stop calling these technologies “artificial intelligence” and start using more accurate terms like large-language models or “likely text generators,” we are more likely to remember that we’re dealing with an impressive predictive text generator, not a thinking intelligence.
References:
[2406.11012] Connecting the Dots: Evaluating Abstract Reasoning Capabilities of LLMs Using the New York Times Connections Word Game. (2024, June 16). arXiv. Retrieved June 28, 2024, from https://arxiv.org/abs/2406.11012
Anlló, H. (2024, June 3). Do Large Language Models reason like us? Research Communities by Springer Nature. Retrieved June 28, 2024, from https://communities.springernature.com/posts/do-large-language-models-reason-like-us
Busch, B. (n.d.). Can AI give better feedback than teachers? InnerDrive. Retrieved June 28, 2024, from https://www.innerdrive.co.uk/blog/ai-vs-teacher-feedback/
Greene, J.A. (2024) Is AI the Smile on a Dog? https://bemusings.ghost.io/ai-objectivity-as-a-smile-on-a-dog/
Hicks, M.T., Humphries, J. & Slater, J. ChatGPT is bullshit. Ethics Inf Technol 26, 38 (2024). https://doi.org/10.1007/s10676-024-09775-5
Kniberg, H. (2024, January 20). Generative AI in a Nutshell – how to survive and thrive in the age of AI. YouTube. Retrieved June 28, 2024, from https://www.youtube.com/watch?v=2IK3DFHRFfw
Messeri, L., Crockett, M.J. Artificial intelligence and illusions of understanding in scientific research. Nature 627, 49–58 (2024). https://doi.org/10.1038/s41586-024-07146-0
Nosta, J. (2024, March 20). Is AI More Creative Than Humans? Psychology Today. Retrieved June 28, 2024, from https://www.psychologytoday.com/us/blog/the-digital-self/202403/is-ai-more-creative-than-humans
Riedl, M. (2023, April 13). A Very Gentle Introduction to Large Language Models without the Hype. Mark Riedl. Retrieved June 28, 2024, from https://mark-riedl.medium.com/a-very-gentle-introduction-to-large-language-models-without-the-hype-5f67941fa59e
Seitchik, A. E. (2024, April 30). AI research and writing companion: A student’s handbook for leveraging technology. OER Commons









{kind=link}